
Every Friday at Bitmetric we’re posting a new Qlik certification practice question to our LinkedIn company page. Last Friday we asked the following Qlik Data Architect certification practice question about Qlik Sense data modelling:

We got a lot of responses this time, showing a lot of good answers but also some discussions about the data models. And reading these discussions we do agree: The official answer should be: “it depends”. Which model is most efficient will always depend on the data provided or requirements of the project. However in case you find yourself sweating over a Qlik certification exam, you should always think “what does Qlik want to hear?“. And in that case:
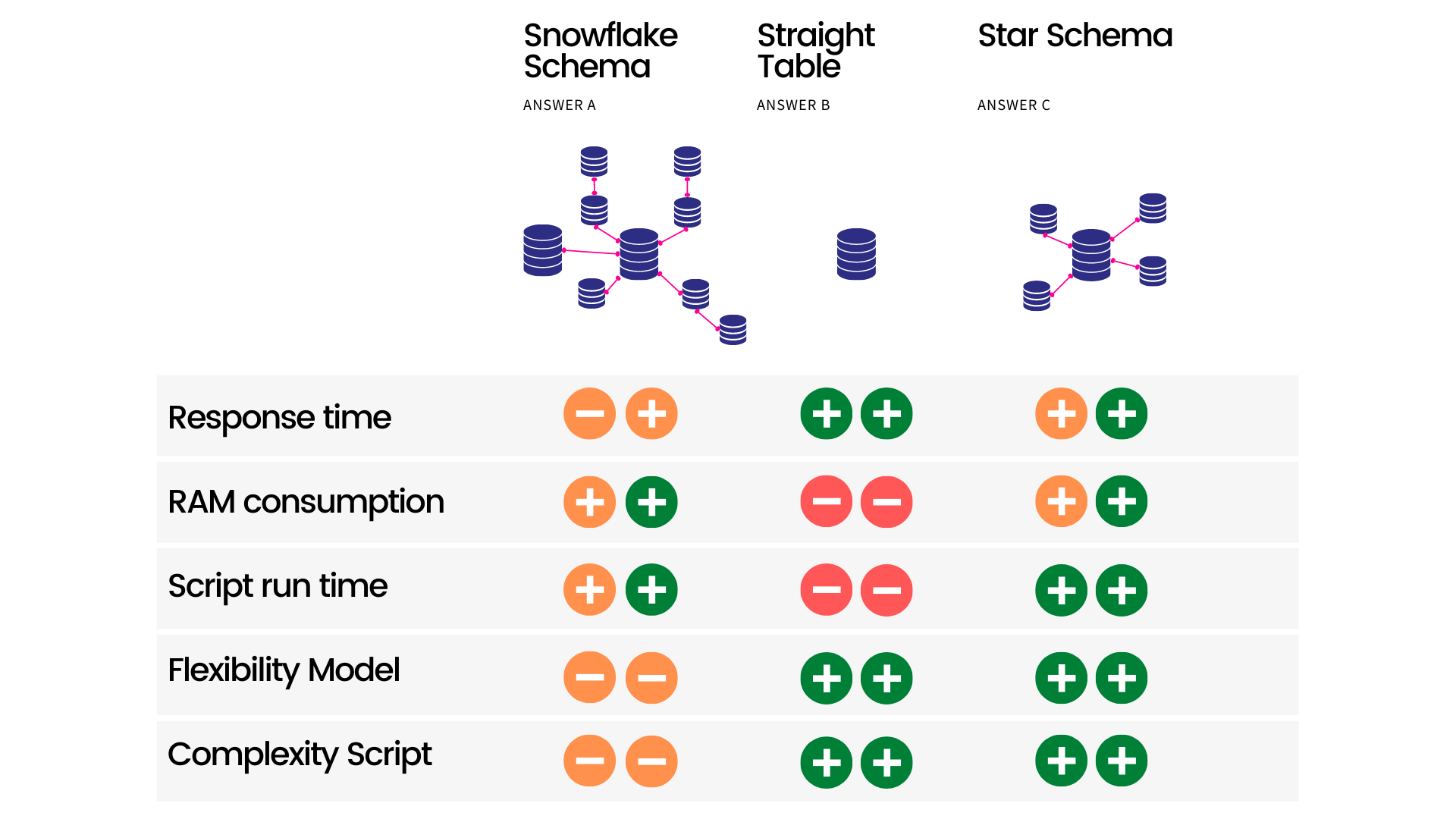
The correct answer is C: A star schema
Since we have phrased the question as “generally speaking” we will not go into depth too much about data modelling, since that is a rabbit hole in itself. However to understand the answer, we need to understand that we are looking at dimensional modelling here and will explain why the star schema is most of the times the preferred model for Qlik.
Entity-Relationship Modelling
Back in the day when relational databases first started to appear Relational Database Management Systems made it easy to store, retrieve and modify the data from these databases. The type of data modelling used was the so called Entity-Relationship Modeling. This aims to Normalize all data. This is the process of removing all redundant data from the database and only storing useful, related data in separate tables. This process makes it very efficient in inserting and updating information in the database. On the downside however, we find that retrieving information from the ER-model databases goes from being less convenient to very difficult. For example a car-lease company could store car related dimensions completely normalized into separate manufacturer, model and fueltype tables. We can imagine that the bigger the dataset the bigger the query grows to retrieve information. Only to get all car information from a single car we need to go through three tables in this case.
Dimensional Modelling
In case Entity-Relationship Modelling becomes too complicated to query, dimensional modelling can offer a solution. A dimensional model consists of a single fact table. The fact table contains a compound primary key, with several other separate keys linking to dimension tables. Next to these keys all important metrics are stored in the fact table.
The dimension tables contain all data that gives context to the metrics stored in the fact table. These dimensions contain data that is often centered around certain levels which are all flattened (denormalized) to give context about a certain topic in the dataset. For example, if we take the database of a car-lease company, the car dimension could contain manufacturer, model and fueltype all in the same dimensional table. This makes that querying information on a single car only needs to go through one table instead of many different tables.
Different models
As we can see from the question asked that there are different types of dimensional models, which we will walk through in short fashion and see how these relate to Qlik. The biggest reasons to use dimensional modelling instead of ER-modelling are ease of use and ease of understanding. It is easier to understand for developers and users how the data is stored and retrieved and which types of data correlate with each other. We identify the following data models in dimensional modelling:
A snowflake schema
A snowflake schema is a partially denormalized schema. Visible in the fact that certain dimension tables are also linked to another table containing further information. With some fantasy the model looks like a snowflake under a microscope.
A star schema
The star schema consists of a single fact table, containing all the measures and the keys to the dimension tables. The biggest advantage being ease of use and understanding for the developers and users. The model is named star schema, since if you really squint your eyes it sort of resembles a star.
The biggest benefit of using dimensional modeling in Qlik applications is the increased response time. Qlik applications work faster when there are fewer links between the tables. For each link between the tables Qlik has to calculate all possibilities of the relationships, making more links increase this calculation time exponentially.
A single table
With the benefit of increased response time in mind, why wouldn’t a single table be the best solution? No links means no calculation time, right? As we stated in the beginning, the answer always is: “it depends”, the following diagram shows why a start schema is generally speaking considered the preferred model, since it offers the best balance between all various trade-offs.
That’s it for this week. See you next Friday?
More from the Bitmetric team

Qlik Cloud Backup
Protect your investment in Qlik with daily incremental backups stored in an encrypted environment with redundant storage. Available for as little as 2 Euro per day. Learn more.

Join the team!
Do you want to work within a highly-skilled, informal team where craftsmanship, ingenuity, knowledge sharing and personal development are valued and encouraged? Check out our job openings.

Rethinking Pop-Ups in Qlik Cloud: A Simple Yet Effective Solution
Struggling with the lack of native pop up support in Qlik Cloud? Learn how we created a smooth and user friendly alternative using guided sheet transitions with only native Qlik functionality. No extensions or layout issues involved.

Qlik Data Flow: Simplifying Data Transformation Without Code
Qlik Data Flow simplifies data transformation with a visual editor. Clean, join, and reshape data using drag and drop, no coding needed. Automatically generate Qlik script as you build. Learn how it works, see a step-by-step example, and compare it to Qlik Data Manager and Qlik Script.
Just because your data is in the cloud does not make it safe.
Qlik Cloud does not automatically back up your data, leaving your apps vulnerable to loss, corruption, or accidental deletion. Learn why a backup solution is essential and how Bitmetric’s Qlik Cloud Backup keeps your data safe. Take action now to protect your analytics